David OhanainITNEXTOn the Safe Side: Log your 3rd-party Package VersionsHow to easily log or print versions of all of your Java dependencies.4 min read·Dec 22, 2021--2--2
David Ohana10 Tips for Machine Learning Experiment Tracking and Reproducibility — Do It Yourself Approach…Fight ML experiment confusion with 10 simple tips that everyone can adopt. No additional 3rd party tooling or platforms are required.9 min read·Nov 21, 2021----
David OhanainThe StartupAvoiding Bash frustration — Use Python for shell scriptsHow to replace bash with Python for shell scripting3 min read·Nov 8, 2020--1--1
David OhanainThe StartupSimple Runtime Profiling of Batch Jobs in ProductionA simple yet effective approach for measuring and optimizing runtime of batch jobs with real-world workloads.4 min read·Nov 2, 2020--1--1
David OhanainThe StartupCode-First Configuration Library for KotlinGitHub repo: https://github.com/davidohana/kofiko-kotlin2 min read·Oct 15, 2020--1--1
David OhanainThe StartupCode-First Configuration approach for PythonA neat new configuration package for Python.4 min read·Jun 28, 2020----
David OhanaHow to restrict user access with to Grafana with Generic OAuthIf you have successfully integrated Generic OAuth with Grafana, you might wonder as I did:2 min read·Jun 17, 2020--1--1
David OhanaPython Retry on ExceptionHow to retry a code block until no exception is raised? Simple and elegant solution.1 min read·May 25, 2020--1--1
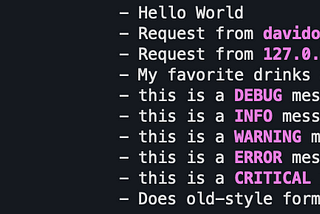
David OhanainAnalytics VidhyaPython Logging: Colorize Your Arguments!Log messages with alternating colors for each argument in the format string, in addition to colorization by log level3 min read·May 24, 2020----
David OhanaLayered Python ConfigParser wrapper with support for environment varsIn every programming language I develop, one of the first thing I need is a decent configuration library.2 min read·May 20, 2020--2--2